



How AI training advances are shaping LLM market competition
AI research might lower the barriers to entry in the highly-valued SOTA and specialized model segments

Investors, researchers, and technology builders are unclear on whether training a model has value or will simply be wiped out by the enxt state-of-the-art (SOTA) advancement. Despite major AI labs like OpenAI, Anthropic, Deepmind (Google), and Meta dominating headlines, there is viable competition and defensibility in the emerging segments of the large language model (LLM) market. Research innovation can reduce the barriers for new or existing companies to successfully move into higher value segments.
The 3-stage LLM Training Process & Significant Challenges
The LLM training process follows a 3-stage training process with significant challenges which limit how many companies are able to reach state-of-the-art (SOTA) performance.
Pre-Training
Models trained on public internet data using self-supervised learning to predict the next word of a statement:
The dog sat on the…
The most recent SOTA models are trained on 10s of trillions of tokens. As the performance of SOTA models pushes further, there is a quadratic scaling penalty - processing 10x more input tokens requires 100x more compute. With diminishing availability of quality internet data and high compute costs, quadratic scaling prevents companies with less capital from building their own pre-trained models.
Instruction Tuning
The pre-trained LLM is undergoes supervised fine tuning with a dataset structured in a user & assistant format such that predicting the next word simulates a conversation:
User: Help me write a story which starts, ‘The dog sat on the…’
Assistant: …
Instruction tuning is a relatively straightforward process compared to pre-training and RLHF where many companies are able to start with an open-source pre-trained LLM and tune it to their own dataset designed for a specific use case.
Reinforcement Learning with Human Feedback (RLHF)
The instruction tuned model is further tuned to produce desired behaviors and discourages unwanted outputs using human annotations to guide a reward model and loss function to encourage these behaviors.
GOOD
User: Help me write a story which starts, ‘The dog sat on the…’
Assistant: The dog sat on the patio for a lazy afternoon nap in the sun.
Compared to…
BAD
User: Help me write a story which starts, ‘The dog sat on the…’
Assistant: The dog sat on the cactus in outer space.
The current predominant implementation of RLHF, proximal policy optimization (PPO), has multiple layers of complexity including increasing difficulty of sourcing deep-expert human annotation as LLMs improve expertise, computational complexity of defining the reward and loss functions, and rudimentary labeling of human preference compared to more detailed guidance on positive and negative characteristics. This complexity combined with limited top-market LLM data science talent creates conditions where only the top research labs willing to pay top dollar can implement high-quality RLHF.
Current Trends Towards a 3-Segment LLM Market
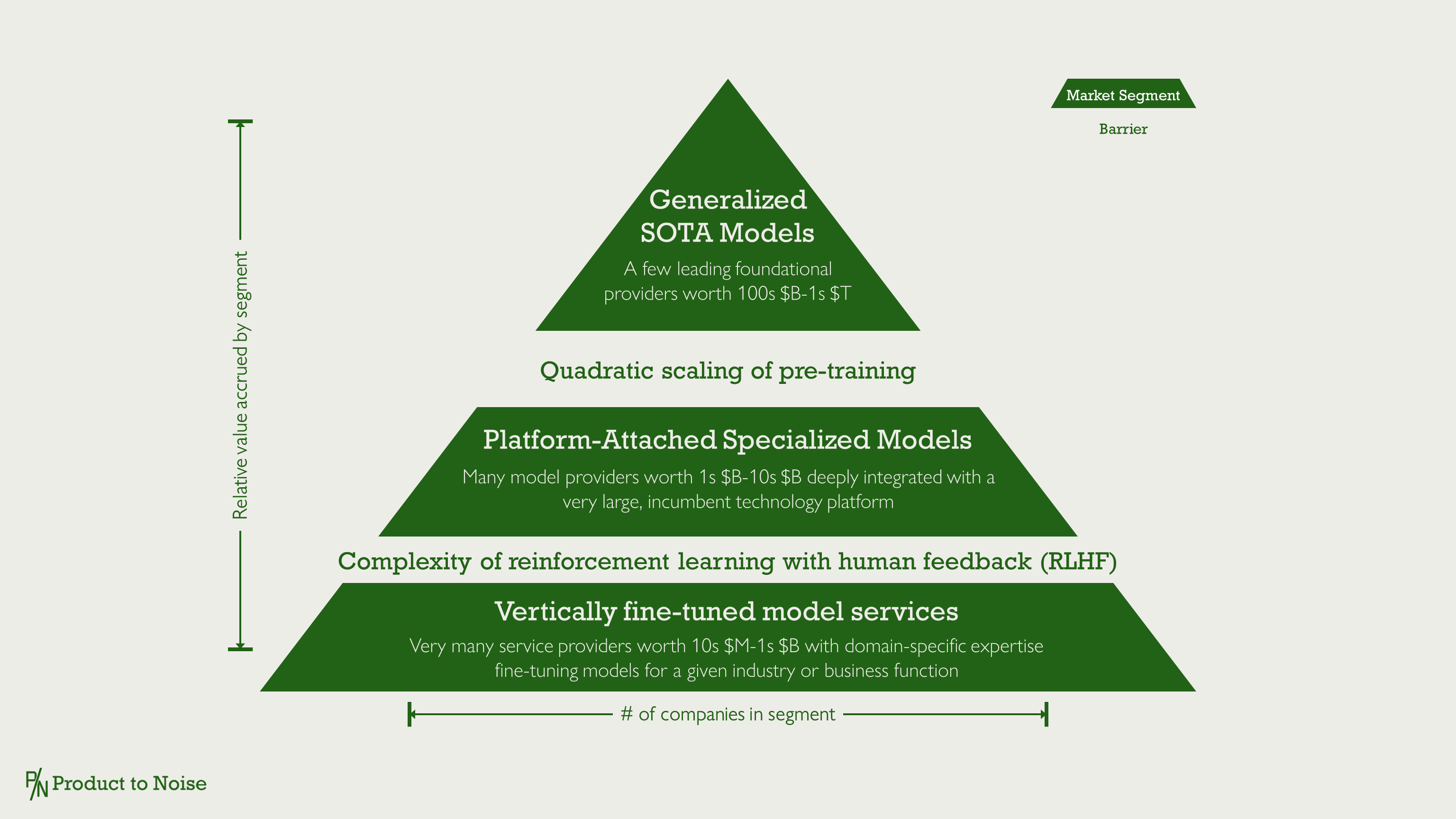
The Hugging Face LMSys Chatbot Arena Leaderboard demonstrates the outcome of significant LLM training challenges in pre-training and RLHF - labs with the most capital who are able to attract the best talent are the leaders. These are the names most people know: OpenAI, Anthropic, Google, and Meta. The generalized SOTA model segment is currently set to accrue the most value between a few players.
Prohibitive challenges of quadratic scaling in pre-training separate SOTA from the next tier of value accrual, platform-attached specialized models. Examples of this segment which have been more prominently featured in AI news include MosaicML acquired by Databricks, Salesforce Einstein, and Inflection acquired by Microsoft. While it may not be the highest value segment, it has the ability to support many players with significantly sized businesses through partnered or owned models with major technology platforms.
The challenge of RLHF creates a final segment of vertically fine-tuned model services. Providers with datasets which are highly specialized to a use case for instruction tuning are building models specialized to industry or business function which they can combine with deep domain expertise to rapidly customize for their customers. It creates market conditions where very man companies can build profitable, but lesser value, companies due to the less scalable services delivery model.
Strategic Considerations for LLM Model Companies
Stay tuned to my substack for more insights into strategic considerations for building LLMs which will include:
Research which might lower the barrier to entry for more companies in higher-value segments
SOTA models aren’t making enough money to sustain development costs plus monetization options
Numerous LLM companies will fail but it isn’t a bubble, it is VC power laws
Platform-attached specialized models have great upside while SOTA gets distracted over the war to achieve AGI
Note: It is incredibly difficult to capture the state of the AI market in a consumable size. For simplicity conveying the key insights on the market with arguably the most activity, I made conscious simplifications to focus specifically on LLMs. I am excited on innovation happening in SLMs, multi-modality, memory architectures, and more. For my favorite, most comprehensive AI market map, please see MAD Market Map.